
Building the harness for RL Coding Agents
Today's AI coding agents can generate impressive volumes of code in a single pass, spinning up entire modules, scaffolding full applications, and writing hundreds of lines in one go. But there's a gap between generating code and shipping code. The output of these long-running sessions is often monolithic and untested. In the real world, predicting edge cases is hard. Usually, you find them when you run your code in production.
The fundamental problem is that these agents don't work the way I do. I don't write 500 lines and push them all to production. I make a small change, run the tests, look at the output, and move on only when I trust the ground beneath me. That's what got me thinking, what if I could get agents to work this way, too? Less prolific code generators, more disciplined engineers who iterate, test, and earn their way forward.
But the question is, how do I actually make this work? I kept coming back to reinforcement learning as a mental model. An RL agent doesn't get handed the perfect path. It explores actions, observes rewards, and iterates until it converges on something that works. I wanted the same loop, but for code.
I've been tinkering with an idea, how to make coding agents work less like one-shot generators and more like senior engineers. Here's how I think it should function
- We define the architectural opinion loosely, set the constraints that you care about, and the architectural patterns you prefer. I kept the context tiered like a lightweight project overview that loads every session, task-specific prompts that load on demand, and a persistent knowledge base that the agent pulls when it needs depth.
- The agent explores multiple strategies: The agent takes my guardrails and spins up multiple approaches, each making different trade-offs. It runs all of them, collects the results, and puts them side by side. In some domains, this comparison is fully automated, such as evals and benchmarks. In others, with a human in the loop, where it's not possible to do evals automatically
- The agent analyzes feedback, adjusts, and iterates inside a sandbox just like an RL agent instance gets its own isolated environment with full permissions, its own ephemeral observability stack. Break things safely, learn, try again
- We set up the reward function. Correctness is the baseline, but production needs richer signals. Code quality, performance, security, and minimal footprint. Getting the reward function right is one of the hardest problems here.
The key difference from how agents work today: there's no human in the middle saying "try this instead." I wanted to build a harness that closes the feedback loop on its own. So let's dive into what that harness actually need?
Building the Harness:
So what I am trying to do is simple: give an agent the ability to make a change, run it, see what happens, and iterate until it works.: That's the loop developers run dozens of times a day: edit, save, test, observe, fix. But building that loop for an autonomous agent requires solving a stack of infrastructure problems
Define Your Architectural Opinion Loosely
What worked for me was not writing a spec, but setting intent. I treated it like telling a senior developer what we care about without micromanaging how they get there. I found that defining three things was enough: what the system needs to do, what shape it should take, and what constraints it has to respect.
For example, when I was building a file processing pipeline, my architectural opinion looked something like: "It needs to read CSVs and parquet files, normalize them into a standard schema, and output JSON. It should be structured as a set of composable transforms, not one monolithic script. And it has to run within a 512MB memory ceiling because this runs on small instances." That was it. We weren't dictating function signatures or class hierarchies. We gave the agent enough to make smart trade-offs on its own.
One thing I noticed was that this is also where the eval starts to take shape naturally. The high-level intent we defined reads these formats, outputs this shape, and stays under this memory limit; these became my success criteria almost for free. If the agent produced code that couldn't handle a Parquet file, or blew past the memory ceiling, or output malformed JSON, we knew it failed without writing a single test by hand. For me, the architectural opinion and the eval turned out to be two sides of the same coin.
How to make effective change
Before the agent writes a single line of code, it needs to figure out what to do. It starts with your architectural opinion and the intent, the constraints, the shape of the solution, and decomposes the problem into concrete steps. Think of it like a developer reading the ticket, scanning the codebase, and sketching a plan before opening their editor. The agent does the same: it identifies what needs to change, where in the codebase it lives, and what the dependencies look like.
The most effective approach isn't a single monolithic instruction file; it's a tiered system.
- Tier 1 loads automatically every session: a structured project overview (CLAUDE.md, AGENTS.md) that serves as the table of contents, not the encyclopedia.
- Tier 2 loads when specific tasks are invoked; a codebase analyzer doesn't carry the prompt for a debugger.
- Tier 3 is the persistent knowledge base: research documents, specs, and session history. Agents pull from this on demand, keeping the primary context window lean. Treat AGENTS.md as the table of contents and maintain the actual knowledge in a structured
docs/directory.
The critical insight: context is a scarce resource. A giant instruction file crowds out the task, the code, and the relevant documentation.
Testing how change works
Agents can produce tons of code, but how do they actually check if it works? The first piece is the sandbox — an isolated environment where the agent can run with full permissions without risking your system. Filesystem isolation, bind mounts, ephemeral observability stacks per worktree. The agent gets to break things freely and learn from them.
OpenAI's Codex team made their application bootable per git worktree, meaning each agent instance gets its own isolated copy of the running application, including its own ephemeral observability stack (logs, metrics, traces).
But the more interesting question is how to test the changes themselves. There are a few layers to this. The first is straightforward: the agent makes a small change, runs the existing test suite, and checks if anything broke. Incremental, disciplined, the way I would do it myself.
The second layer is where it gets more powerful. Before the agent even writes code, it looks at the feature and tries to figure out what this thing should ideally do, the full surface area, the happy paths, the edge cases, the failure modes. It's essentially building a mental map of the problem space.
Then comes the third layer and this is the one I find most interesting. Instead of letting the agent write its own tests and mark its own homework, bring in a separate adversarial agent whose only job is to break things. It looks at the code, the intent, the constraints, and generates test cases designed to find holes the original agent didn't think about. It's like having a colleague whose entire purpose is to poke at your PR and ask "but what happens when..." The agent that writes the code and the agent that tests it should never be the same, that tension is where the real quality comes from.
Building the feedback loop
Observe how the software behaves in the wild, and learn from what comes back. But the nature of that feedback varies dramatically depending on what you're building.
Infrastructure — Deploy to a cluster that mirrors production, run evals, and watch what breaks or where is not able to fulfill the requirement.
APIs — Contract tests. Your consumers define what they expect, and your Test fails if you violate those contracts.
Frontend — Put a prototype in front of 5 real users and watch them use it. Usability testing catches things no automated test ever will: confused clicks, missed CTAs, misread copy.
BI / Analytics — Reconciliation against a trusted source of truth. Pick a known number, verify your pipeline produces the same answer. If it doesn't, nothing else matters.
Data Science / ML — An eval suite with labeled golden examples. It's the closest thing ML has to a unit test suite, and it's the single best investment you can make.
Mobile — Beta distribution. Get the build into real hands-on, real devices before it hits the app store.
For frontend and mobile, it's tougher; you might need a real person looking at a screen to tell you if something feels off. But regardless of how easy or hard that feedback is to get, let's assume you have it.
OpenAI's internal team demonstrated this at scale: three engineers using Codex produced roughly 1,500 pull requests over five months, averaging 3.5 PRs per engineer per day, across a codebase that grew to over a million lines of code. The humans didn't write code. They designed the harness, specified intent, and provided feedback. The agent did the rest.
Once you have the harness providing structure, the sandbox providing the environment, the loop providing the iteration, and the reward function providing direction, agents can do remarkable things.
Defining the Reward Function
The harness gives the agent structure. The reward function tells it what "good" looks like. Getting this right is one of the hardest problems in agent engineering.
For SWE-bench-style tasks, the reward function is relatively clean: the patch must fix the specific bug or implement the feature (fail-to-pass tests now pass), and the patch must not break existing functionality (pass-to-pass tests continue to pass). Both conditions must be met. This binary signal — resolved or not — is simple and effective for benchmarking. But production software engineering needs richer reward signals. A few dimensions that matter:
Correctness is the baseline, but does the code do what it's supposed to? Tests are the primary signal, but test coverage is often incomplete.
Code quality encompasses readability, maintainability, adherence to project conventions, and absence of code smells. This is harder to measure automatically, but linters, static analysis tools, and code review agents can approximate it.
Performance matters for certain tasks. Does the change introduce latency, increase memory usage, or create scalability bottlenecks? Benchmarks and profiling tools provide this signal.
Security is non-negotiable. Does the change introduce vulnerabilities? Static analysis, dependency scanning, and security-focused review agents contribute here.
Minimal footprint rewards precision; the best patch changes only what needs to change. An agent that rewrites half the codebase to fix a one-line bug is technically correct but practically dangerous.
The Inner Loop: Change → Test → Observe → Fix → Check Reward → Release.
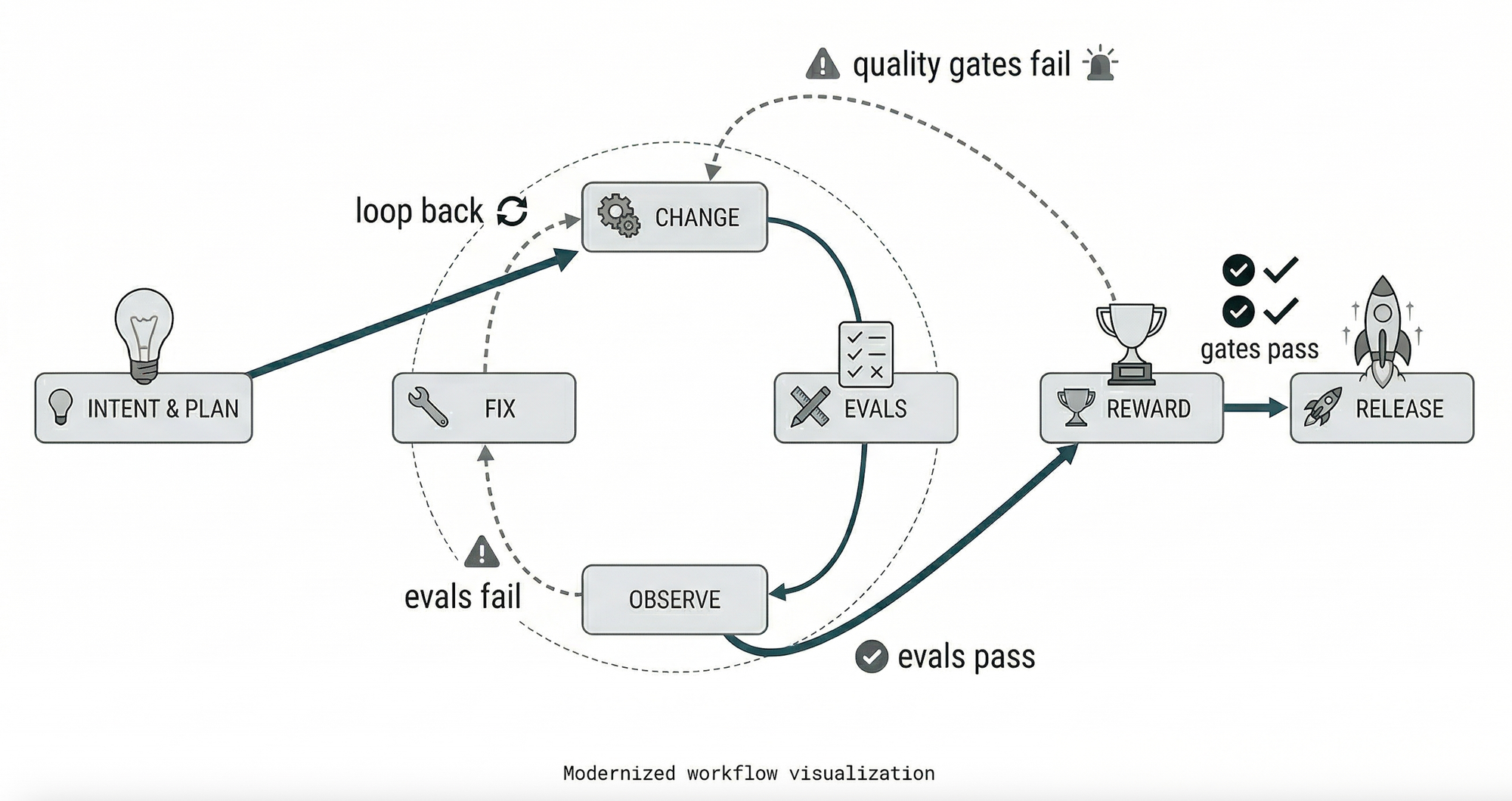
Every task flows through a disciplined cycle. The agent researches the relevant code, plans an approach, executes changes in the sandbox, verifies through the test loop, and either releases via PR or escalates with a detailed progress report. When something fails, the fix is rarely "try harder," it's asking "what capability is missing, and how do we make it legible and enforceable for the agent?"
What's next?
Over the next few weeks, I'm building a harness that lets me iterate on ideas and software at high speed. It won't just write code and test it; it will deploy to real environments, collect real-world feedback and opinionated input, and use reinforcement learning to close the loop. Take the feedback, weigh the opinions, pit competing approaches against each other, find the best solution, build it, test it, deploy it, all in a tight inner loop. The end goal: produce output that doesn't just work, but passes as a polished, shippable product.