
GPU Snapshots for Reducing ML Inference Cold Starts
Before diving into GPU snapshotting, it's important to understand the foundation laid by CPU virtualization technologies. Firecracker is a virtualization technology developed by AWS that creates lightweight virtual machines (microVMs) with minimal overhead.
Traditional CPU snapshotting in Firecracker allows you to:
- Capture the complete state of a running VM (CPU registers, RAM contents, device states)
- Restore that exact state later, resuming execution instantly
- Skip initialization overhead like OS boot, application startup, and data loading
This works well for CPU-based workloads but faces limitations with modern ML applications that rely heavily on GPUs. GPUs maintain state across multiple layers (driver, CUDA runtime, device memory). GPUs traditionally haven't supported the same virtualization primitives as CPUs until 2025
GPU snapshotting captures a running container’s entire state – including GPU memory (model weights), CUDA contexts, and other GPU driver state – and restoring it later so that the model does not need to reload. In essence, we “freeze” the GPU state with the model already in memory and load it on demand, achieving instant readiness.
Cold start is the delay when an ML service is started and must load models into memory (and GPU) before serving requests. On modern GPUs like the NVIDIA A100/A10/L40s, models like Stable Diffusion/Qwen3 (multi-gigabyte) can take 30+ seconds to load the state.
Limitations of CUDA Checkpointing
- Process ID Dependency – During restoration, CRIU requires the exact process ID. This makes CUDA checkpoint restores brittle, as the restored container must map back to the original PID context.
- Mount Propagation and Lock Handling – Shared memory locks (eg /dev/shm) require special handling in
runc. Without proper configuration, CRIU may fail to dump or restore GPU processes reliably. - TCP Connection Recovery – Active socket connections are difficult to fully restore. Even if processes are checkpointed, host-level TCP sessions may not reattach cleanly, limiting seamless container restoration.
NVIDIA’s CUDA-checkpoint utility introduced support for toggling and capturing CUDA state within the same process. Let's dive into how to use this with criu
Four Key Technologies for Container Restore with GPU
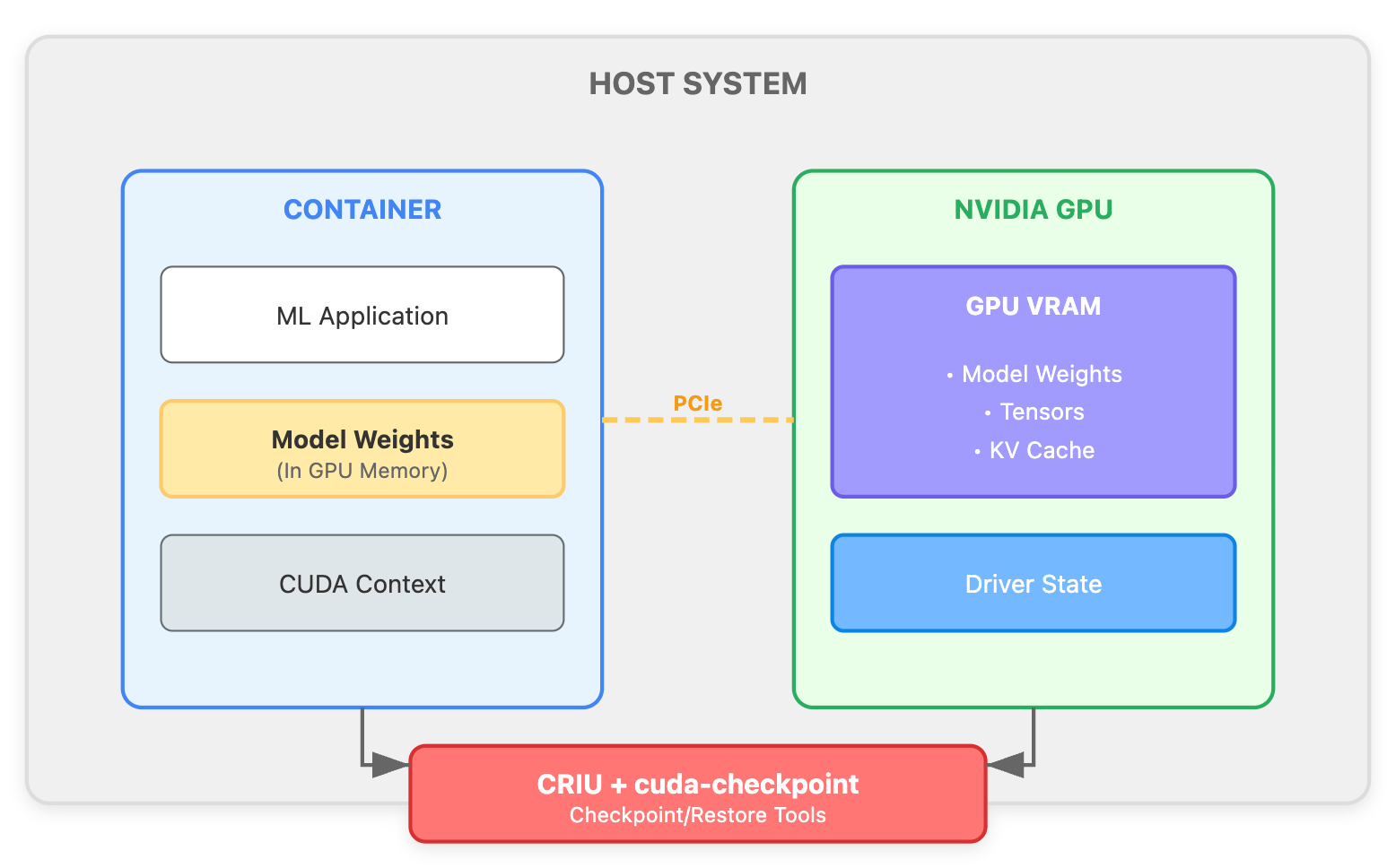
CRIU (Checkpoint/Restore In Userspace) -Freezes and captures Linux process state saves memory pages, file descriptors, and network connections acts as the orchestrator for the entire checkpoint operation
NVIDIA cuda-checkpoint - Extends CRIU to understand GPU state captures CUDA contexts, GPU memory, and kernel state ensures GPU operations can resume exactly where they left off
Container Runtime (runc) - Podman provides high-level checkpoint/restore commands runc bridges between Podman and CRIU manages container lifecycle and namespaces
NVIDIA Container Toolkit - Exposes GPU devices to containers which provides necessary device nodes (/dev/nvidia*) and ensures proper GPU access permissions
Architecture - Checkpoint/Restore Flow
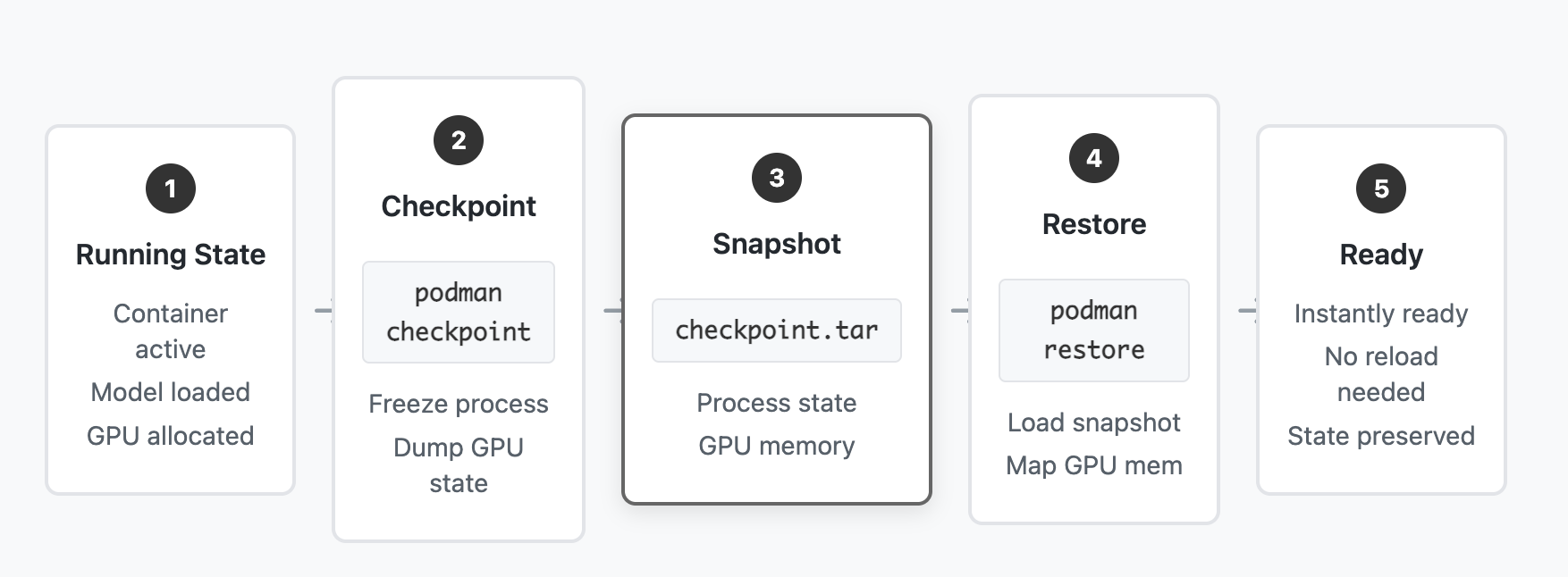
Checkpoint Process:
1. Application Running → Podman checkpoint command issued
2. Podman → Instructs runc to checkpoint container
3. runc → Invokes CRIU with configured options
4. CRIU → Freezes process and calls cuda-checkpoint
5. cuda-checkpoint → Captures GPU state (VRAM, contexts)
6. CRIU → Dumps CPU state, memory, file descriptors
7. Combined state → Exported as tar archiveRestore Process:
1. Podman restore command → Imports checkpoint archive
2. runc → Invokes CRIU restore with saved state
3. CRIU → Restores CPU process state and memory
4. cuda-checkpoint → Restores GPU memory and contexts
5. CRIU → Re-establishes file descriptors and sockets
6. Container → Resumes execution from checkpointNow. Let's deep dive into how to make this magic happen for Containers
1 ) Prerequisites and Environment Setup
- Hardware: A system with an NVIDIA GPU running Ubuntu 24.04/22.04. You should have root or sudo privileges on this system.
- NVIDIA Driver: Installed NVIDIA drivers (version ≥ 570) on the host is required for CUDA checkpoint support.
- Kernel: A Linux kernel new enough to support CRIU features (Ubuntu 24.04’s default kernel should suffice for CRIU 4.1).
Installing CRIU 4.1 with NVIDIA CUDA Support
First, install the latest CRIU (Checkpoint/Restore in Userspace), which includes GPU support. CRIU 4.1 (released March 2025) or above is recommended, as version 4.0 introduced the NVIDIA CUDA plugin and 4.1 brought further improvements. Ubuntu 24.04 may not ship this version by default, so we will either use the official CRIU PPA or build from source:
Install from CRIU PPA (Personal Package Archive). The CRIU project provides a PPA with newer builds.
# Install CIRU 4.1
sudo add-apt-repository ppa:criu/ppa -y
sudo apt update
sudo apt install -y criu
After installation, verify the version ( should be 4.1+ ):
criu --version
Installing NVIDIA’s cuda-checkpoint Utility
Next, obtain cuda-checkpoint, NVIDIA’s utility that manages the GPU state during checkpoint/restore. This tool is essential – CRIU will call into it (or the underlying driver APIs) to freeze and restore the GPU state of our process. NVIDIA provides cuda-checkpoint via their GitHub repository. It supports driver version 550+ and is distributed as a standalone binary.
To install cuda-checkpoint:
Download the binary: The easiest method is to grab the pre-built binary from NVIDIA’s GitHub. For example:
git clone https://github.com/NVIDIA/cuda-checkpoint.git
sudo cp cuda-checkpoint/bin/x86_64_Linux/cuda-checkpoint /usr/local/bin/
sudo chmod +x /usr/local/bin/cuda-checkpoint
Test the utility: Run:
cuda-checkpoint --help
2 ) Installing Podman and runc (Container Runtime)
We will use Podman to run and manage our container, as it has built-in support for checkpoint/restore using CRIU. Podman is a daemonless container engine (an alternative to Docker) , also supports CRIU, and has better support for checkpoint and restore. We also need the OCI runtime runc (which Podman uses under the hood by default) because runc has the hooks to coordinate with CRIU for checkpointing. (If you don't want podman, you can also use containerd with runc for snapshot and restore )
Install Podman and runc on Ubuntu 24.04:
sudo apt update
sudo apt install -y podman runc
After installation, check versions:
podman --version
runc --version
Ensure Podman is reasonably up-to-date (v4.4+). Podman will automatically detect CRIU if the criu binary is in PATH. You can verify Podman sees CRIU by running:
podman info | grep -i criu
If everything is set, this should show checkpoints support as available.
Edit Podman’s default runtime in /etc/containers/containers.conf to "runc". For example:
[engine]
runtime = "runc"
Using runc is important because it will invoke CRIU with the proper configuration file (/etc/criu/runc.conf) and has the necessary code to handle the CRIU restore process.
Configuring CRIU (runc.conf) for Container Checkpointing
Why link-remap & tcp-established?
During checkpoint, CRIU may encounter unlinked file handles (e.g., deleted files that a process still has open, or NFS file handles) and fail by default. The link-remap tells CRIU to create temporary hardlinks for such files so that they can be saved
We will add this setting, and also take the opportunity to enable tcp-established to support checkpointing of open network connections (useful if our container maintains a listening socket).
sudo tee /etc/criu/runc.conf > /dev/null << EOF
# CRIU options for runc/Podman container checkpoint/restore
tcp-established
link-remap
EOF
3) Setting Up NVIDIA Drivers and Container GPU Access
Before launching the container, let’s ensure the NVIDIA GPU is accessible inside containers. We have installed the NVIDIA driver on the host, but we need a mechanism to pass the GPU device to Podman containers. We will use the NVIDIA Container Toolkit which supports Podman via the Container Device Interface (CDI).
Install NVIDIA Container Toolkit: This provides the necessary hook or CLI for exposing GPUs to containers. On Ubuntu, install the toolkit package:
distribution="ubuntu22.04"
curl -s -L https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg
curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list
sudo apt update
sudo apt install -y nvidia-container-toolkit
Generate the CDI specification for GPUs: NVIDIA Container Toolkit can generate a CDI device profile for the GPUs on the system. This allows Podman to request GPUs by a logical name.
sudo nvidia-ctk cdi generate --output=/etc/cdi/nvidia.yaml
Test GPU access with Podman: Let’s do a quick smoke test to confirm everything is wired up:
sudo podman run --rm --device nvidia.com/gpu=all docker.io/nvidia/cuda:12.8.1-base-ubuntu22.04 nvidia-smi
This command runs the official CUDA base image and executes nvidia-smi inside. If configured correctly, you should see the usual GPU summary table printed
4) Testing the Snapshot/ Restore for ML application
Starting the container so that it can be snapshotted
export CONTAINER_NAME="cuda-counter-standard"
sudo podman run -d --device nvidia.com/gpu=all \
--device /dev/null:/dev/null:rwm \
--name "$CONTAINER_NAME" \
--mount type=bind,source=/dev/nvidia0,target=/dev/nvidia0,bind-propagation=private \
--mount type=bind,source=/dev/nvidiactl,target=/dev/nvidiactl,bind-propagation=private \
--mount type=bind,source=/dev/nvidia-uvm,target=/dev/nvidia-uvm,bind-propagation=private \
--privileged \
-p 8080:8080 \
docker.io/nileshagarwal/stable-diffusion-2-1:latest
Why are they needed?
- /dev/nvidia0 → This is the actual GPU device file (your A100 in this case). Without binding it inside the container, CRIU cannot freeze GPU state or restore it, since CUDA contexts live in the GPU.
- /dev/nvidiactl → Control interface for the NVIDIA driver. Required for managing GPU resources, setting up contexts, and coordinating with the kernel driver.
- /dev/nvidia-uvm → Unified Virtual Memory (UVM) driver node. This is crucial if CUDA apps use UVM, which most modern ML frameworks do. It lets CRIU track and restore memory mappings between CPU and GPU.
Why bind-propagation=private ?
This ensures the bind mounts are isolated to the container — changes inside won’t propagate back to the host or other containers. Snapshotting and restoring works cleanly without side effects on the rest of the system.
Snapshoting the Container
sudo podman container checkpoint \
--export="$WORK_DIR/container-checkpoint-sd.tar" \
--tcp-established \
--ignore-rootfs \
--ignore-volumes \
"$CONTAINER_NAME"
Why ?
- --tcp-established→ Checkpoints open TCP sockets so running services (e.g., inference servers with active connections) can resume without reconnecting.
- --ignore-rootfs → Avoids snapshotting the container’s root filesystem since it’s immutable and already part of the Podman image. Makes checkpoint/restore faster.
- --ignore-volumes → Excludes external volumes (like data or model storage) from the snapshot. Assumes they’ll still be mounted on restore, preventing large/unnecessary dumps.
What this does:
- Freezes the container’s processes.
- Uses CRIU (with our configured options) to dump the container state to checkpoint images.
- Saves those images into an archive file $WORK_DIR/sd_checkpoint.tar.
Now you can distribute this to restore the container on any machine
Migrating the GPU Snapshot to Another Machine
One powerful use of checkpoint/restore is to migrate a running workload across machines (live migration) or to preload an image on multiple machines. To try this, you need a second machine (target) with the same setup as the source: Ubuntu 24.04, NVIDIA driver (same version), CRIU 4.1 + cuda-checkpoint, Podman+runc, and ideally the same GPU model
1) Load the container’s image if not present.
sudo podman pull nileshagarwal/stable-diffusion-2-1:latest
2) Transport the Artifact for the Restoration
aws s3 cp s3://<bucket>/snapshots/<ml-service>/checkpoint.tar ./sd_checkpoint.tar
Restoring the Container from a GPU Snapshot
With the checkpoint in hand, we can restore the container. Restoration can be done on the same host or a different host.
sudo podman container restore \
--import="$WORK_DIR/container-checkpoint-sd.tar" \
--tcp-established \
--ignore-rootfs \
--ignore-volumes
Verifying Post-Restore Inference Functionality
Let’s hit the inference endpoint of the restored container to ensure it responds correctly. Using the same test as before (adjust as needed for the actual API of the container):
curl -X POST http://localhost:8080/v2/models/stable-diffusion/infer -H "Content-Type: application/json" -d '{"text": "a horse near a lake"}'
Performance Implications and Benefits
With the above setup, we have effectively eliminated the cold-start penalty for our ML model by using GPU snapshotting. Let’s reflect on performance and practical benefits:
Cold Start Latency Reduction: After checkpointing, starting (restoring) the container is much faster than a fresh start. Instead of paying the cost to load weights from disk to GPU and compile kernels (which could be tens of seconds), restore simply memory-maps the saved GPU state. In research by the CRIUgpu project, they achieved restore times of only a few seconds for single-GPU models
vLLM benefits a lot. You skip the heavyweight “cold boot” path (weight load → CUDA/NCCL init → graph/autotune warmups) and restore a pre-warmed GPU state instead.
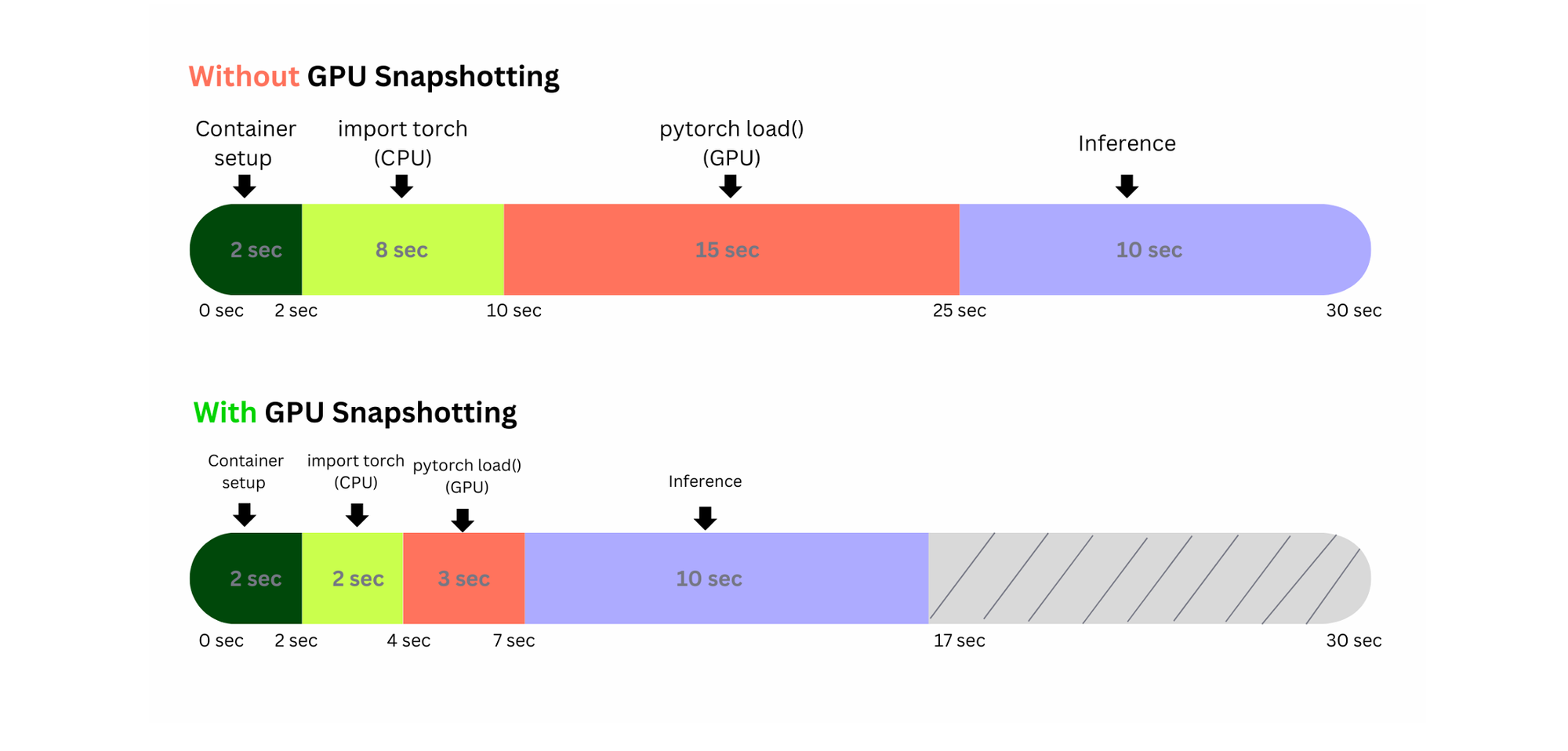
What snapshotting removes in LLM
- Weight transfer to VRAM (several–tens of seconds for large models) → restored from a GPU memory snapshot rather than reloading from disk over PCIe.
- CUDA context + handles + autotune “first pass” (cuBLAS/cuDNN setups, allocator warmup) → captured and restored.
- PagedAttention/KV cache pool & page tables priming (post-warmup state) → captured after a short dummy run; avoids re-profiling during engine init.
- Torch.compile / compiled graph cache reloads (if you warm once before snapshot) → you restore with compiled artifacts already resident.
In summary, we set up a working solution to eliminate cold starts for an ML model container using CRIU and cuda-checkpoint. The restored container was immediately ready to serve inference requests without re-loading model weights. This technique can dramatically improve the responsiveness of GPU-based microservices and enable more efficient utilization of expensive GPU resources (by allowing you to spin VMs/containers down when idle and bring them back up quickly when needed).