
Making AI Argue With Itself
I've been running background agents overnight, queuing up a list of tasks before bed, and waking up to pull requests in the morning. The code works. But then I spent half the next day arguing with the agent about edge cases, error handling, and structural decisions it made at 3 AM. That kept bugging me a lot.
When I write code myself, I have a mental checklist. Am I handling errors? Are there edge cases I'm missing? Is this secure? With AI-generated code, I found myself spending more time reviewing than I saved generating. And the irony is: I was using one AI to write and then manually doing the adversarial thinking myself.
That felt backwards. If AI can write code, why can't another AI try to break it?
This is the core idea behind adversarial development. Instead of a single AI producing code and hoping for the best, you pit two models against each other — one builds, one attacks — and iterate until the code converges on something solid. The builder has to satisfy the attacker. The attacker has to find real problems. The bar keeps going up.
What I Found Missing in Existing Tools
I looked at what was already out there. There are a few projects that wire Claude and Codex together — things like review loops, code-then-review pipelines, and multi-agent coding setups. They all share the same basic shape: generate code, review it, maybe fix it, and ,done.
The gaps I kept hitting:
No convergence detection. These tools run for a fixed number of iterations or until one side says "looks good." But "looks good" after iteration 3 might not mean the code is actually stable — maybe the reviewer just got less strict. There's no measurement of whether the code is actually getting better or just churning.
No stale loop detection. I watched loops spin for 20 minutes,, making the same changes back and forth. The reviewer would flag something, the builder would fix it but break something else, the reviewer would flag the new thing, and round and round. Nobody was tracking whether progress had stalled.
No accumulating quality bar. Reviews are stateless. Each cycle, the reviewer looks at the code fresh and gives a thumbs up or down. But what about the issue it flagged last cycle — did that actually get fixed? There's no memory of what was asked for, no checklist that grows over time.
No pluggable standards. Every team has its own coding standards, security requirements, and architectural preferences. Existing tools hardcode their review criteria or leave it entirely to the model's judgment. There's no way to say, "here are our rules, enforce these specifically."
No structured eval. The closest thing to evaluation is "did the tests pass?" But passing tests doesn't mean the code follows your standards, handles edge cases gracefully, or is structured well. Tests check behavior; eval checks quality.
Building Review Into the Loop
The fix isn't adding more review steps — it's making review a first-class part of the iteration cycle itself. Every time the agent produces code, something should be actively trying to break it. Not once at the end, but every cycle, with memory of what came before.
Concretely, that means a few things. The reviewer needs state — it should know what it flagged last round and verify it actually got fixed, not just look at the code fresh each time. It needs to accumulate standards, so when it spots a missing pattern like input validation, that becomes a permanent requirement for every future cycle. It needs to track whether the code is actually improving or just churning — are diffs getting smaller, are issues going down, or are we stuck in a loop where fixing one thing breaks another?
And critically, this has to happen before the engineer ever sees the code. The whole point of running agents overnight is leverage — you wake up to code that's already been stress-tested, not code that passed a green CI check but falls apart the moment you read it. The adversarial layer should be doing the arguing you'd do in review, except it did it at 3 AM across multiple cycles while you slept.
This is the difference between a pipeline that runs linting and tests at the end and a system that applies compounding pressure throughout. One gives you code that passes checks. The other gives you code that survived a fight.
CAAT: Claude Adversarial AutoTurn
So I built CAAT. The idea is simple: Claude builds, Codex attacks, repeat until the code is good — not just "it runs".
A CAAT run has seven phases per cycle:
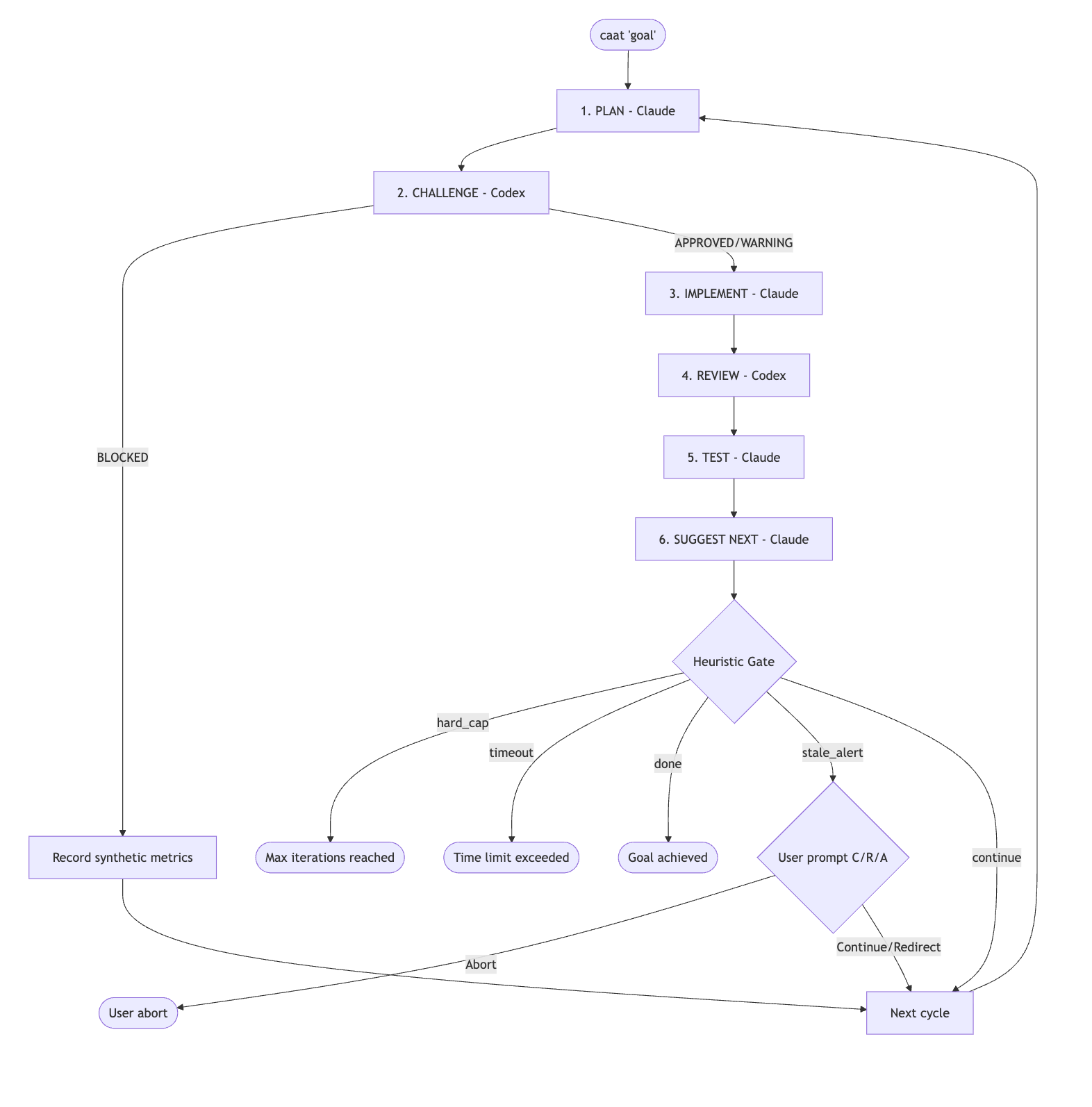
- Plan — Claude creates an implementation plan based on your goal
- Challenge — Codex tries to poke holes in the plan before any code is written
- Implement — Claude writes the code, incorporating the challenger's feedback
- Review — Codex reviews the actual implementation
- Test — Claude runs tests and fixes failures
- Eval — Claude checks the code against every accumulated quality criterion
- Suggest Next — Claude decides if the goal is complete or what to do next
If Codex blocks the plan in phase 2, implementation is skipped entirely and Claude re-plans. No wasted cycles writing code that was doomed from the start.
The Eval System
This is the part I'm most excited about. You define eval criteria upfront:
caat --eval "All functions have type hints; No function exceeds 30 lines" "Build a REST API"
But here's the twist: each cycle, Codex can add new criteria. If the reviewer notices the code has no input validation, it adds "All endpoints validate input" to the eval list. These criteria accumulate — the eval gets harder, not easier. By cycle 3, you might have twice the criteria you started with, all of which must pass.
This creates genuine adversarial pressure. The builder can't just satisfy the original requirements and call it done. The attacker keeps raising the bar.
Skills
Skills are pluggable review guidelines — markdown files that get injected into the challenge, review, and eval phases. CAAT ships with a built-in coding-best-practices skill covering error handling, security, testing, and performance. You can add your own:
caat --skills-dir ./team-standards "Build an auth module"
Drop a markdown file in the directory with your team's rules, and every cycle will enforce them. Skills also contribute to eval criteria, so they're not just suggestions — they're requirements.
Convergence
CAAT tracks a composite delta metric across cycles: review findings, test results, issue scores, and diff size. If the code stops improving — same issues cycling back and forth, tests not getting greener, diffs not shrinking — CAAT detects the stale loop and asks you what to do: continue, redirect, or abort.
This was a direct response to watching loops spin uselessly. The convergence engine gives you a quantitative answer to "is this making progress?"
What It Looks Like
══════ CYCLE 1/3 ══════
Skills: 1 built-in loaded
Eval: 3 initial criteria
Phase 1/7: PLAN (Claude)...
Plan created (13.3s)
Phase 2/7: CHALLENGE (Codex)...
Verdict: WARNING | Critical: 0 | High: 1 (57.8s)
Eval: +2 criteria from Codex (total: 5)
Phase 3/7: IMPLEMENT (Claude)...
Implementation done (35.4s)
Phase 4/7: REVIEW (Codex)...
Verdict: APPROVED | Critical: 0 | High: 0 (45.9s)
Phase 5/7: TEST (Claude)...
Result: PASS | 41/41 passing (32.4s)
Phase 6/7: EVAL (Claude)...
Eval: 5/5 passed (ALL PASS) (18.2s)
Phase 7/7: SUGGEST NEXT (Claude)...
GOAL COMPLETE! (9.2s)
One command, and your code goes through plan review, adversarial challenge, implementation, code review, testing, and quality evaluation — all automatically.
The Meta Moment
The most satisfying test was running CAAT on itself. I pointed it at its own codebase and told it to improve the tool. Codex correctly identified missing features, Claude implemented them, and the adversarial loop caught real issues I'd missed. It added its own __main__.py entry point, fixed a goal-completion bug, and wrote tests for edge cases I hadn't considered.
If your adversarial coding tool can improve itself, that feels like it's working.
CAAT is open source, just point it at a goal, and let AI argue with itself until the code is right. Would love to hear your thoughts and learnings, reach out to me on X here.
Thanks, Zak, for brainstorming the concept, and Ash, for reviewing and editing the blog.